RAG実装完全ガイド:エンタープライズ向けLLMアプリケーション構築
はじめに:RAGが解決するビジネス課題
2023年のChatGPTの登場以来、多くの企業が大規模言語モデル(LLM)の活用を検討しています。しかし、実際に導入しようとすると、「LLMが自社のデータを知らない」「最新情報に対応できない」「ハルシネーション(虚偽情報)を生成する」といった課題に直面します。
Retrieval-Augmented Generation(RAG)は、これらの課題を解決する革新的なアプローチです。本記事では、RAGの基本概念からエンタープライズ向けの本格的な実装方法まで、実践的な知識を体系的に解説します。
RAGの本質:知識の動的拡張
従来のLLM活用の限界
LLMは膨大なデータで学習された強力なモデルですが、いくつかの根本的な制約があります。
第一に、学習データのカットオフ問題です。例えばGPT-4は2023年4月までのデータで学習されており、それ以降の出来事や情報については知りません。
第二に、企業固有情報の欠如です。社内規程、製品仕様、顧客データなど、公開されていない情報にLLMはアクセスできません。
第三に、ハルシネーションのリスクです。LLMは確率的に「それらしい」回答を生成するため、事実と異なる情報をあたかも真実のように述べることがあります。
RAGの革新性
RAGは、これらの課題を「検索」と「生成」の組み合わせで解決します。ユーザーの質問に対して、まず関連する情報をデータベースから検索し、その情報をコンテキストとしてLLMに提供することで、正確で最新の情報に基づいた回答を生成できるようになります。
例えば、「当社の2024年第3四半期の売上は?」という質問に対して、通常のLLMは回答できませんが、RAGを使えば社内の財務データベースから該当情報を取得し、正確な回答が可能になります。
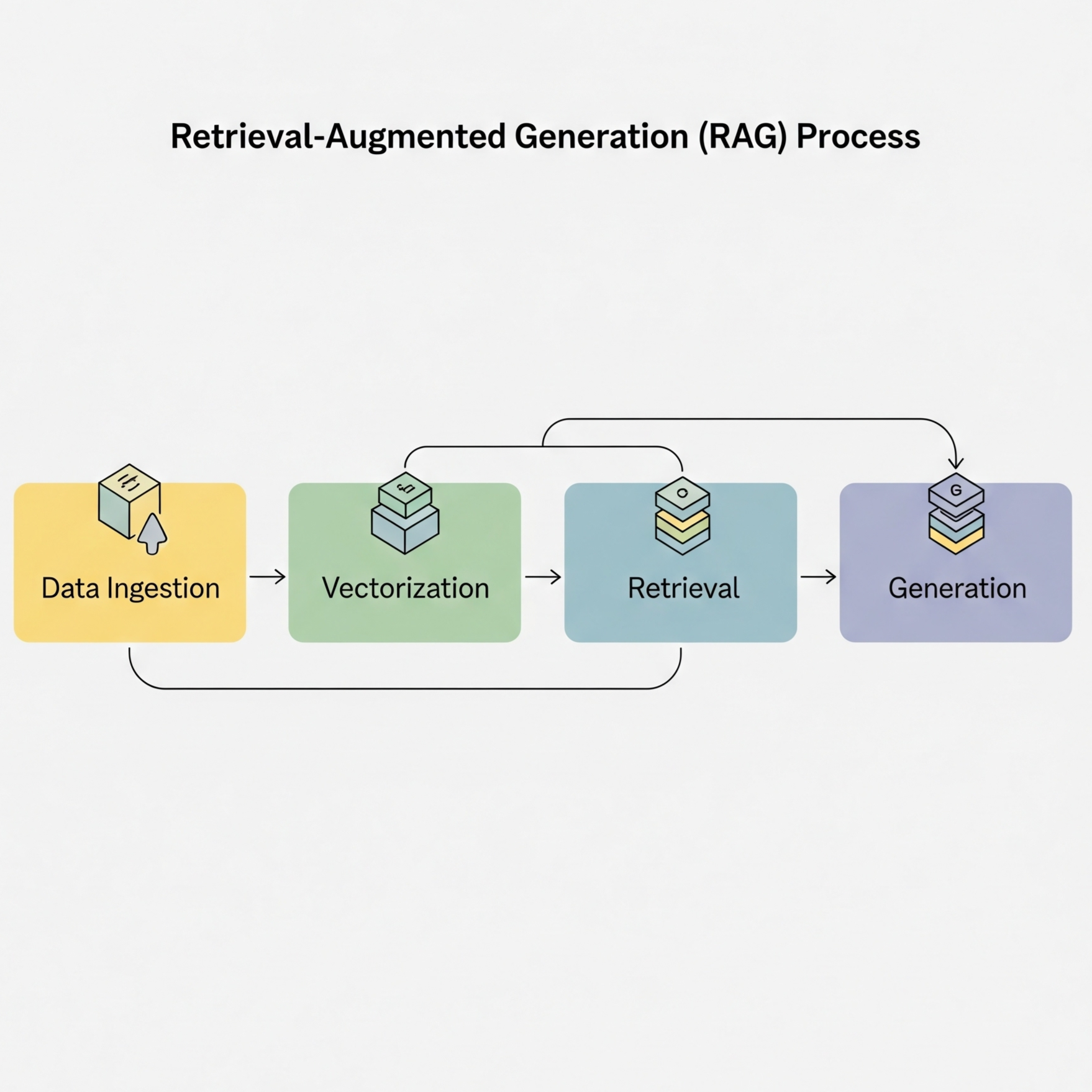
RAGシステムのアーキテクチャ
全体像と処理フロー
RAGシステムは、大きく4つの処理段階で構成されます。
1. クエリ処理段階 ユーザーからの質問を受け取り、検索に適した形式に変換します。この段階では、質問の意図を理解し、不要な要素を除去し、検索キーワードを抽出します。
2. ベクトル化と検索段階 処理されたクエリを数値ベクトルに変換し、ベクトルデータベースで類似度検索を実行します。これにより、意味的に近い文書を高速に検索できます。
3. コンテキスト構築段階 検索結果から関連性の高い文書を選別し、LLMに提供するコンテキストを構築します。この際、文書の順序、量、フォーマットなどを最適化します。
4. 回答生成段階 コンテキストと質問をLLMに入力し、回答を生成します。生成された回答は、必要に応じて後処理や検証を経てユーザーに返されます。
主要コンポーネントの役割
RAGシステムを構成する各コンポーネントは、それぞれ重要な役割を担っています。
ドキュメント処理層は、生データをRAGシステムで扱える形式に変換します。長い文書を適切なサイズに分割し(チャンキング)、各チャンクをベクトル化し、メタデータを抽出します。
ストレージ層は、ベクトルデータと元文書を効率的に保存・管理します。ベクトルデータベース、ドキュメントストレージ、キャッシュシステムなどで構成されます。
検索層は、クエリに対して最も関連性の高い文書を見つけ出します。ベクトル検索だけでなく、キーワード検索やメタデータフィルタリングを組み合わせたハイブリッド検索、再ランキング機能などを含みます。
生成層は、検索結果を基に最終的な回答を作成します。LLMの選定、プロンプトテンプレートの設計、回答の検証や後処理などがこの層の責任範囲です。
実装ステップ1:ドキュメントの準備と前処理
チャンキング戦略の重要性
RAGシステムの性能は、ドキュメントをどのように分割(チャンキング)するかに大きく依存します。適切なチャンクサイズと分割方法の選択は、検索精度と回答品質に直接影響を与える重要な要素です。
主要な分割戦略として、固定サイズ分割、セマンティック分割、階層的分割の3つのアプローチがあります。
固定サイズ分割は最もシンプルな手法で、文書を一定の文字数(通常1000文字程度)で機械的に分割します。実装が簡単で処理速度が速い反面、文の途中で分割される可能性があり、文脈が失われるリスクがあります。オーバーラップ(通常200文字程度)を設定することで、境界付近の情報損失を軽減できます。
セマンティック分割は、文章の意味的な区切り(句点、段落、セクション)を基準に分割する手法です。自然な文章の流れを保持できるため、検索精度の向上が期待できます。各チャンクが完結した意味を持つように分割することで、LLMが理解しやすいコンテキストを提供できます。
階層的分割は、文書の構造(見出しレベル、章立て)を活用した分割方法です。マークダウンやHTMLの見出しタグを基準に、文書を論理的な単位で分割します。この手法により、文書の構造情報を保持しながら、関連する内容をまとめて取得できるようになります。
実践的には、これらの手法を組み合わせたハイブリッドアプローチが推奨されます。例えば、まず階層的に分割し、その後各セクションをセマンティックに細分化するといった方法です。
メタデータの戦略的活用
メタデータの適切な管理は、RAGシステムの検索精度と効率性を飛躍的に向上させます。単なる文書の付加情報ではなく、検索戦略の核となる重要な要素として位置づけるべきです。
基本メタデータとして管理すべき項目には、ファイルパス、タイトル、作成者、作成日時、更新日時、ファイルタイプ、言語などがあります。これらは自動的に抽出可能で、基本的なフィルタリングに活用できます。
ビジネスメタデータは、組織固有の要件に基づく情報です。部門、プロジェクト、機密レベル、承認ステータス、有効期限などが含まれます。これらのメタデータにより、コンテキストに応じた適切な情報提供が可能になります。
派生メタデータは、内容分析から生成される情報です。要約、キーワード、感情分析結果、トピック分類などが該当します。これらは検索の精度向上に大きく貢献しますが、生成にコストがかかるため、必要性とのバランスを考慮する必要があります。
メタデータの活用により、「2024年以降に更新された技術文書」や「経営層が承認した戦略文書」といった複雑な条件での検索が可能になり、ユーザーの意図により適合した結果を提供できます。
ステップ2:埋め込みベクトルの生成
埋め込みモデルの選択
RAGシステムの中核となる埋め込みベクトルの生成には、目的や予算に応じて異なるモデルを選択できます。主要な選択肢として、OpenAIのtext-embedding-3-largeモデル(高精度・3072次元)、Cohereのembed-multilingual-v3.0(多言語対応)、そしてintfloat/multilingual-e5-large(ローカル環境での日本語対応)があります。
效率的な埋め込み生成のため、テキストのバッチ処理を実装しています。通常100件づつのバッチで処理し、APIコールのオーバーヘッドを最小限に抑えます。このアプローチにより、大量の文書を効率的に処理できるようになります。
クエリ処理においては、特別な最適化を行います。クエリ拡張機能では、元のクエリに同義語や関連語を追加し、より幅広い検索を可能にします。これにより、ユーザーが異なる語彙や表現を使用した場合でも、関連する文書を適切に発見できる確率が向上します。
ステップ3:ベクトルデータベースへの保存
Pineconeを使った実装例
生成された埋め込みベクトルの効率的な保存と検索のために、Pineconeのようなマネージドベクトルデータベースを活用します。システム初期化時には、環境変数からAPIキーと環境情報を取得し、指定されたインデックスに接続します。
ベクトルの挿入処理では、各チャンクの埋め込みベクトル、ユニークID、そしてメタデータ(テキスト内容、ソース情報、チャンクインデックスなど)を組み合わせて保存します。PineconeのAPI制限を考慮し、100ベクトルごとのバッチ処理で効率的にアップロードし、レート制限を回避するためにバッチ間で適切な間隔を設けています。
検索機能では、クエリの埋め込みベクトルを使用して類似度検索を実行し、指定された件数(topK)の結果を取得します。メタデータフィルター機能を使用することで、特定のカテゴリ、日付、権限などの条件に基づいた結果の絞り込みも可能です。検索結果には、マッチしたチャンクの類似度スコア、テキスト内容、関連メタデータが含まれます。
ステップ4:ハイブリッド検索の実装
ベクトル検索とキーワード検索の組み合わせ
高精度な検索結果を得るため、ベクトル検索とキーワード検索を組み合わせたハイブリッドアプローチを実装します。ハイブリッド検索サービスでは、ベクトルストアとElasticsearchのようなキーワード検索エンジンを組み合わせて使用します。
検索処理では、ベクトル検索の重みをデフォルトで0.7、キーワード検索の重みを0.3に設定し、両方の検索を並列で実行します。これにより、セマンティックな类似性と完全一致のキーワード次方の利点を活用できます。
スコア結合のプロセスでは、まずベクトル検索結果を管理し、その後キーワード検索結果を追加または結合します。同じ文書が両方の検索で見つかった場合、各々のスコアに重みを適用して結合し、最終的なスコアでソートします。
さらなる精度向上のため、Cross-Encoderモデルを使用したリランキングを実装しています。このステップでは、クエリと各検索結果のペアを直接評価し、より精密な関連性スコアを算出して、最終的なランキングを決定します。ms-marco-MiniLM-L-12-v2のような事前訓練済みモデルを使用することで、効率的で高品質なリランキングを実現します。
ステップ5:コンテキスト構築と生成
効果的なプロンプト構築
RAGシステムの最終ステップであるコンテキスト構築では、検索で得られた文書を効果的なプロンプトに変換します。コンテキストビルダーでは、システムプロンプト、最大コンテキスト長、スコア表示の有無、ソース情報の含有などのオプションを設定できます。
コンテキスト構築のプロセスでは、検索結果を関連性の高い順に取得し、指定された最大コンテキスト長(デフォルトは4000文字)を超えないように文書を選別します。この际、各文書のフォーマットには、オプションで関連度スコアやソース情報を含めることができます。
プロンプトテンプレートの設計では、システムプロンプト、コンテキスト情報、ユーザーの質問、そして回答の指示を明確に分離して構造化します。特に重要なのは、コンテキストに根拠がない情報の生成(ハルシネーション)を防ぐための明確な指示と、回答に必要な情報源の明記です。このアプローチにより、信頼性が高く検証可能な回答を生成できます。
回答生成と後処理
RAGジェネレーターは、構築されたコンテキストを使用して言語モデルから回答を生成し、後処理を通じて品質を向上させます。生成パラメータでは、デフォルトでtemperatureを0.3に設定して一貫性のある回答を促し、最大1000トークンの制限で簡潔な回答を実現します。リアルタイムアプリケーションの場合は、ストリーミングモードで漸次的な回答表示もサポートします。
生成プロセスでは、コンテキストビルダーで作成されたプロンプトを言語モデルに送信し、回答とともに生成時間やトークン使用量などのメタデータも記録します。これらの情報は、システムのパフォーマンス監視やコスト管理に活用されます。
後処理フェーズでは、生成された回答からソース情報を抽出し、ファクトチェックを実行し、クリーンアップを行います。ソースの抽出は正規表現を使用して「[Source: ファイル名]」パターンを検出し、重複を除去して一意なソースリストを作成します。
信頼度スコアの算出では、検索結果の上位3件の関連性スコアの平均を取り、0から1の範囲で正規化します。このスコアは、ユーザーに回答の信頼性を伝える重要な指標となります。
パフォーマンス最適化
キャッシング戦略
大規模なRAGシステムでは、レスポンス時間の短縮とコスト削減のために効果的なキャッシング戦略が不可欠です。RAGキャッシュシステムでは、Redisを使用した完全一致キャッシュと、类似したクエリを検出するセマンティックキャッシュの二層構造を採用しています。
キャッシュ検索のプロセスでは、まずクエリの完全一致をチェックし、一致するエントリがあれば即座に結果を返します。完全一致がない場合は、クエリの埋め込みベクトルを生成し、セマンティックキャッシュ内で類似度の高いクエリ(類似度が0.95以上)を探します。このアプローチにより、表現の違いに関係なく类似したクエリに対して高速レスポンスを提供できます。
キャッシュ保存時には、Redisへの完全一致エントリとメモリ内セマンティックキャッシュへの登録を同時に行います。TTL(Time To Live)はデフォルトで1時間に設定し、古いエントリの自動削除も実装してメモリリークを防いでいます。
バッチ処理とストリーミング
大量のクエリを効率的に処理するために、バッチRAGプロセッサーでは並列処理と順次処理の両方をサポートしています。バッチサイズはデフォルトで5件に設定され、システムのリソースとレート制限を考慮したバランスを保っています。
並列処理モードでは、クエリをバッチごとに分割し、各バッチを同時に処理します。このアプローチでは、メモリ使用量とネットワーク負荷のバランスを取りながら、全体的なスループットを大幅に向上させます。一方、順次処理モードは、リソース制約が厳しい環境や、順序が重要な場合に適しています。
並列バッチ処理の最適化技法として、まず全クエリの埋め込みを一括生成し、その後ベクトル検索と回答生成をそれぞれ並列で実行します。このパイプライン化により、APIコールのオーバーヘッドを最小限に抑え、システム全体のレスポンシブ性を大幅に改善できます。
評価とモニタリング
RAGシステムの評価指標
RAGシステムの品質とパフォーマンスを測定するために、包括的な評価システムを実装します。RAGエバリュエーターでは、主要な評価指標としてコンテキスト精度(検索された文書の関連性)、コンテキスト再現率(必要な情報の網羅度)、回答の忠実性(コンテキストへの一致度)、回答の関連性(クエリへの適合度)、平均レイテンシ、スループットを計測します。
評価プロセスでは、事前に準備されたテストケースを使用して並列評価を実行します。各テストケースに対して、RAGシステムにクエリを送信し、生成された回答と検索されたソースを期待値と比較して各指標を算出します。
精度と再現率の計算では、検索されたソースと期待されるソースを比較し、忠実性と関連性の評価では、別の言語モデルや特化された評価モデルを使用して客観的なスコアを算出します。全ての結果は集計されて平均値が算出され、システムの総合的なパフォーマンスを定量的に評価できるようになっています。
トラブルシューティング
よくある問題と解決策
RAGシステムの運用中には、様々な問題が発生する可能性があります。ここでは、代表的な問題とその解決策を体系的に整理します。
1. 検索精度が低い問題
現象:ユーザーの質問に対して、関連性の低い文書が検索される、または期待する情報が検索されない。
主な原因:
- チャンクサイズが不適切(大きすぎる、または小さすぎる)
- 埋め込みモデルの不一致(クエリと文書で異なるモデルを使用)
- メタデータフィルターの誤設定
- セマンティックギャップ(ユーザーの表現と文書の表現の不一致)
解決策:
- チャンクサイズを500~1500トークンの範囲で調整し、最適値を見つける
- クエリと文書の埋め込みに同一のモデルを使用するよう統一
- メタデータフィルターの条件を再検討し、過度な絞り込みを避ける
- クエリ拡張や同義語辞書を導入してセマンティックギャップを埋める
2. 応答速度が遅い問題
現象:ユーザーの質問から回答までに時間がかかりすぎる。
主な原因:
- ベクトル検索の非効率(インデックス最適化不足)
- コンテキストサイズが大きすぎる
- キャッシュ機能の未実装または不適切な設定
- リランキング処理の過剰な実装
解決策:
- ベクトルデータベースのインデックス設定を最適化(HNSWパラメータの調整)
- コンテキストの最大サイズを3000~4000文字に制限
- Redisなどを使用したキャッシュ層の実装
- リランキングを必要最小限に、または非同期処理で実装
3. ハルシネーション(虚偽情報生成)の問題
現象:検索した文書に存在しない情報をLLMが生成してしまう。
主な原因:
- コンテキスト情報の不足
- プロンプトの制約条件が不明確
- LLMの温度パラメータが高すぎる
- 検索結果の関連性が低い
解決策:
- 検索結果の件数を5~10件に増やし、コンテキストを充実させる
- プロンプトに「コンテキストにない情報は生成しない」という明確な制約を追加
- 温度パラメータを0.1~0.3の低い値に設定
- 検索結果の関連性スコアに闾値を設け、低スコアの結果を除外
4. コストの問題
現象:API利用料が予想以上に高額になる。
主な原因:
- 不必要に大きいコンテキストの使用
- キャッシュの未実装で同じクエリを繰り返し処理
- 高価なモデルの過剰使用
解決策:
- コンテキストサイズを最適化し、必要最小限の情報のみを含める
- セマンティックキャッシュを実装し、類似クエリの再計算を避ける
- ユースケースに応じてより小さいモデルを選択(GPT-3.5など)
まとめ:成功するRAG実装のために
RAG実装の今後の展望
本記事では、RAGシステムの基本概念から実装の詳細、最適化手法、トラブルシューティングまで、包括的に解説してきました。RAG技術は、企業が保有する知識資産とLLMの能力を組み合わせる最も実用的なアプローチとして、今後も進化を続けていくでしょう。
特に注目すべき今後のトレンドとして、マルチモーダルRAG(テキストだけでなく画像や表データも統合)、エージェント型RAG(能動的な情報収集と検索)、グラフRAG(知識グラフを活用したより高度な推論)などが挙げられます。
また、埋め込みモデルの進化やベクトルデータベースの性能向上により、より高速で高精度なRAGシステムの実現が可能になるでしょう。
実装チェックリスト
RAGシステムを構築する際には、以下のポイントを確認してください:
ドキュメント処理 ✅ 適切なチャンキング戦略の選択 ✅ メタデータの体系的な管理 ✅ 多様なファイル形式への対応
検索システム ✅ 高品質な埋め込みモデルの選定 ✅ 効率的なベクトルデータベースの構築 ✅ ハイブリッド検索の実装検討
生成システム ✅ 効果的なプロンプトエンジニアリング ✅ コンテキストサイズの最適化 ✅ ハルシネーション対策の実装
性能最適化 ✅ キャッシング戦略の設計 ✅ バッチ処理の実装 ✅ 非同期処理の活用
運用・保守 ✅ 評価指標の設定とモニタリング ✅ エラーハンドリングとフォールバック ✅ セキュリティとアクセス制御
最後に
RAGシステムの実装は、技術的な挑戦と同時に、組織に大きな価値をもたらす機会でもあります。本記事で紹介した知識とベストプラクティスを活用し、ぜひ自社のニーズに適したRAGシステムを構築してください。
成功の鍵は、小さく始めて段階的に改善していくことです。まずはシンプルなプロトタイプから始め、ユーザーのフィードバックを取り入れながら、継続的にシステムを改善していくアプローチをお勧めします。
関連記事

コンテキストエンジニアリング完全ガイド:プロンプトエンジニアリングを超えた次世代AI開発
LLMアプリケーション開発の新パラダイム「コンテキストエンジニアリング」の基礎から実践まで、RAGやベクトルDBを活用した実装方法を徹底解説

ベクトル検索の落とし穴と効率的なRAG構築 - ハイブリッド検索による本番運用レベルのシステム設計
RAGシステムにおけるベクトル検索の限界と、レキシカル検索を組み合わせたハイブリッド検索の必要性を技術的に解説。本番環境で求められる精度と再現率を両立する実践的なアーキテクチャを提案します。

ベクトルデータベース徹底比較 2025:Pinecone vs Weaviate vs Chroma vs Qdrant
主要なベクトルデータベースを性能、機能、コスト、使いやすさの観点から徹底比較。プロジェクトに最適な選択を支援